Le contenu du blog
Ayant un background de développeur, j’ai toujours recherché des générateurs de sites statiques pour mes blogs. De cette façon je peux configurer mon site/blog comme je le veux en ayant les mains proches du code. J’ai un attachement pour le générateur de sites Hugo simplement car il est écrit en Go. Ce n’est pas du tout la meilleure manière de faire un choix technologique, mais j’assume mon choix. Pour des choix alternatifs, vous pouvez regarder Jekyll, Eleventy et Gatsby. Le but ici est d’avoir un site web statique qui ne sera que des fichier .html, .css et .js. Pour le cas de ce blog, je vous invite à lire le quick start d’Hugo.
Lorsque nous avons une bonne structure de base, nous pouvons pousser le projet sur un repository git. Pour notre exemple, il sera sur GitHub.
Petite note importante, il est préférable d’avoir un .gitignore à la racine de notre repository. Voici celui que j’utilise pour Hugo.
# Generated files by hugo
/public/
/resources/_gen/
/assets/jsconfig.json
hugo_stats.json
# Executable may be added to repository
hugo.exe
hugo.darwin
hugo.linux
# Temporary lock file while building
/.hugo_build.lock
L’architecture
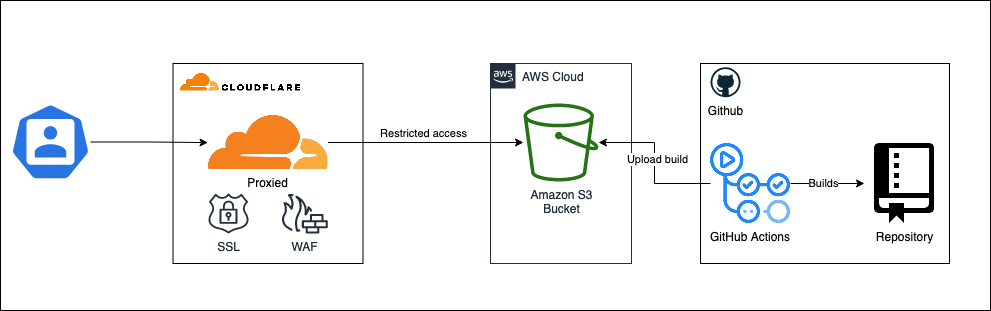
Le blog est hébergé sur AWS S3. Je ne couvrirai pas comment s’inscrire à AWS, je crois que leur documentation fera un meilleur travail que moi à cet égard. Pour le rendre disponible nous utiliserons Cloudflare.
Tout le contenu du bucket S3 que nous créerons sera fourni par un repository GitHub et les GitHub Actions.
Pourquoi S3 et Cloudflare?
S3 (Simple Storage Service) est le service de stockage d’AWS. Nous l’utiliserons car il est très peu coûteux (voir gratuit si vous êtes sur le free tier). Nous pouvons héberger un site web statique sur un bucket avec quelques configurations supplémentaires. De plus, je crois qu’il est important de toucher un peu à S3 car il est un service important parmi ceux qu’AWS offre.
Nous aurions pu utiliser CloudFront qui est le service CDN d’AWS, mais Cloudflare est entièrement gratuit pour les mêmes fonctionnalités que nous aurions utilisé (CDN, SSL, Caching). D’un point de vue mise en place, utiliser Cloudflare comporte moins d’étapes que CloudFront (nous aurions eu à passer par ACM, Route53 et faire plusieurs configurations sur CloudFront).
S3
Creation d’un bucket
Le point de départ pour avoir un site qui roule est de créer un bucket. Rendons-nous sur la page du service S3 et cherchons le bouton pour créer un bucket.
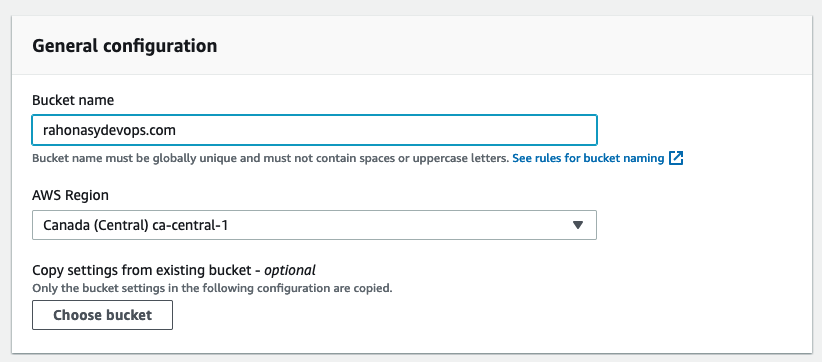
Lorsque nous créons votre bucket, nous devons lui donner comme nom notre domaine complet. Par exemple, ici mon bucket se nomme rahonasydevops.com.
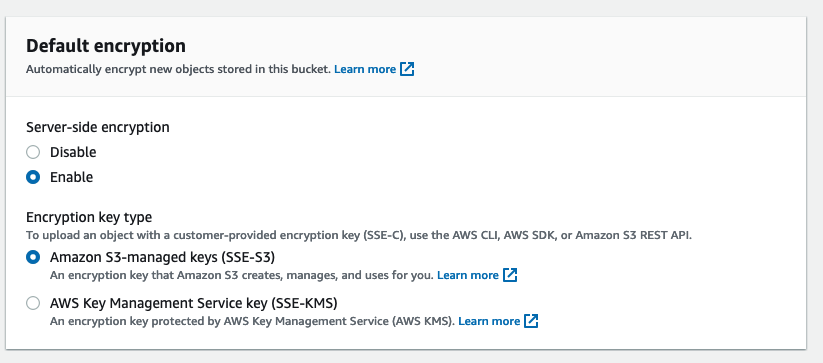
Je conseille également d’activer l’encryption et le versioning. Bien que nous ayons un site public, avoir de l’encryption est un bon réflexe pour quand nous aurons des buckets qui contiendront des données sensibles.
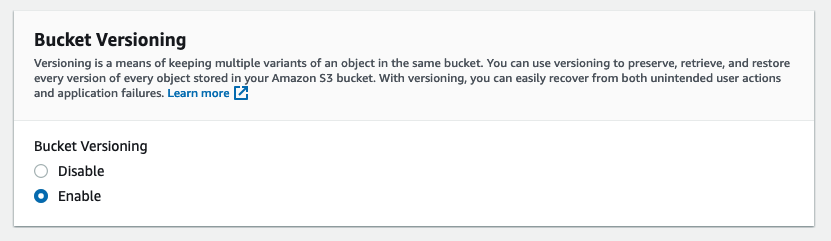
Activer le static website hosting
Maintenant que notre bucket est créé, allons vers l’onglet Properties. Tous en bas, nous trouverons la section Static website hosting. Cliquons sur Edit.

Nous allons activer le hosting et indiquer index.html comme Index document.
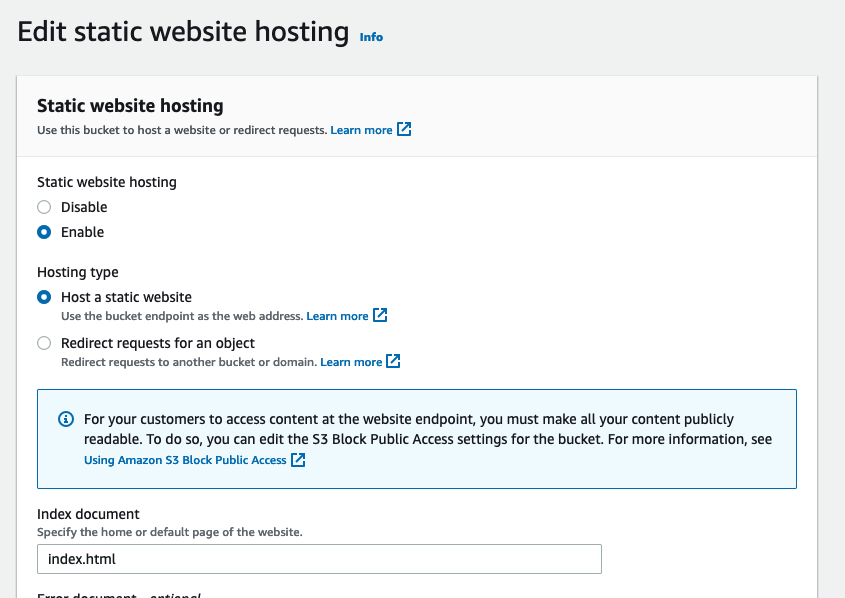
Donnez accès au bucket à Cloudflare
À l’écran de notre bucket S3, sous l’onglet Permissions, il y aura une section Bucket policy dans laquelle nous allons mettre une policy comme celle-ci:
{
"Version": "2008-10-17",
"Id": "PolicyForCloudflarePrivateContent",
"Statement": [
{
"Sid": "PublicReadForGetBucketObjects",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<BUCKET_NAME>/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": [<CLOUDFLARE_IPS_HERE>]
}
}
}
]
}
Nous pouvons trouver les IPs de Cloudflare ici: https://www.cloudflare.com/en-ca/ips/. Il suffira de remplacer la balise <CLOUDFLARE_IPS_HERE> sous forme de valeur en JSON. (Par exemple: "1.1.1.1/32", "2.2.2.2/32", ...). N’oublions pas de spécifier le nom de notre bucket en remplaçant <BUCKET_NAME>.
Dernière chose à faire dans S3, retournons sous l’onglet Properties dans la section Static website hosting et notons le Bucket website endpoint qui ressemblera à ceci: http://<BUCKET_NAME>.s3-website.<AWS_REGION>.amazonaws.com
Cloudflare
Commençons par nous créer un compte sur Cloudflare. Je laisse à votre discrétion comment vous allez gérer votre domaine. Vous pouvez acheter votre domaine via Cloudflare ou le faire ailleurs et faire pointer vos Nameservers sur ceux de Cloudfront. Voici un guide intéressant à cet égards: https://developers.cloudflare.com/registrar/get-started/
Lorsque le compte Cloudflare est créé, nous allons déléguer à Cloudflare les responsabilités de gérer notre site.
Commençons par ajouter un site via le dashboard: https://developers.cloudflare.com/fundamentals/get-started/setup/add-site/.
Lorsque celui-ci est configuré, il suffit de créer une entrée DNS. Nous allons créer un CNAME avec @ comme Name et comme Value le endpoint que nous avons noté plus haut: http://<BUCKET_NAME>.s3-website.<AWS_REGION>.amazonaws.com (en prenant soin d’utiliser les bonnes valeurs de nom de bucket et de région.)

Voilà! D’un point de vue infrastructure, notre blog est prêt. Il ne reste qu’à copier les fichiers du site statique vers le bucket!
Le déploiement
AWS IAM
Afin de permettre à GitHub de jouer dans notre bucket S3, nous devons créer un utilisateur qui agira pour nous. Le service AWS qui nous permet de faire cela est IAM. Dans IAM, nous allons simplement créer une policy et un utilisateur avec lequel nous ne pourrons pas nous authentifier.
Sur la page IAM, dans la section Policy, nous allons cliquer sur Create policy. Pour simplifier la chose, nous allons aller à l’onglet JSON et mettre la valeur que nous voulons directement.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Deploy",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetBucketWebsite",
"s3:ListBucket",
"s3:DeleteObject",
"s3:GetBucketAcl",
"s3:GetBucketLocation",
"s3:GetObjectVersion",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::<LE_NOM_DE_VOTRE_BUCKET>",
"arn:aws:s3:::<LE_NOM_DE_VOTRE_BUCKET>/*"
]
}
]
}
Sauvegardons le tout en donnant à la policy un nom significatif.
Pour créer l’utilisateur, nous allons aller dans la section Users et faire Add users
Dans la prochaine page, nous allons donner le droit à cet utilisateur de déployer dans le bucket S3. La manière la plus rapide, mais loin d’être la meilleure, sera d’attacher notre policy directement à cet utilisateur. La bonne pratique est d’attacher une policy à un groupe et ajouter notre utilisateur à ce groupe. En poursuivant notre création d’utilisateur, nous aurons finalement un Access Key ID et un Secret Access Key. Notez ces valeurs et NE LES DIVULGUEZ JAMAIS.
GitHub
On ne réinvente pas la roue pour déployer notre blog. En bonne pratique DevOps, nous opterons pour du CI/CD grâce au GitHub Actions.
Il nous suffira d’ajouter, à partir de la racine de notre repository git, l’arborescence suivante: .github/workflows/deploy-website.yml. Le nom du fichier est à votre discrétion. Voici le contenu que j’utilise.
name: Build and Deploy
on:
push:
branches: [main]
pull_request:
jobs:
build:
runs-on: ubuntu-22.04
steps:
- uses: actions/checkout@v3
with:
submodules: true # Fetch Hugo themes (true OR recursive)
fetch-depth: 0 # Fetch all history for .GitInfo and .Lastmod
- name: Setup Hugo
uses: peaceiris/actions-hugo@v2
with:
hugo-version: '0.105.0'
extended: true
- name: Build
run: hugo --minify
- uses: actions/upload-artifact@v3
with:
name: build
path: public/
retention-days: 7
deploy:
runs-on: ubuntu-22.04
needs: build
if: github.ref == 'refs/heads/main'
steps:
- name: Download a build folder
uses: actions/download-artifact@v3
with:
name: build
path: public
- uses: jakejarvis/s3-sync-action@master
with:
args: --acl public-read --follow-symlinks --delete
env:
AWS_S3_BUCKET: ${{ secrets.AWS_S3_BUCKET }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_REGION: 'ca-central-1'
SOURCE_DIR: 'public'
Quelques notes intéressantes
- Nous remarquons l’utilisation des secrets pour faire références aux données sensibles. Il est donc impératif d’ajouter les clés que nous avions obtenues dans IAM dans les secrets.
- L’utilisation de git submodules qui est “propre” à Hugo, car les thèmes d’Hugo sont généralement des sous modules git dans votre repository.
- Je build toujours afin de m’assurer que le “code” du blog est ok.
- Les artéfacts générés par notre build sont passés entre plusieurs jobs.
Conclusion
Voilà! Voici les grandes étapes qui permettent d’avoir un blog comme celui-ci. Avez-vous remarqué quelque chose de bizarre? Nous avons fait pas mal d’étapes dans AWS et Cloudflare à la main. Ce n’est pas très DevOps tout ça! Dans mon prochain post, nous reconstruirons le blog au complet en faisant du Infrastructure as Code (IaC). À suivre!